
Kernel Methods
Linear Algebra Terminologies
Relevantly, note that
The normalised vector is thus
Thus, given column vectors:
with the dot product of
Note that the dot product gives the similarity of two vectors:
- larger dot product indicates similarity
- smaller dot product indicates dissimilarity
Support Vector Machine Concepts
Summary
- Dual formulation of linear regression
- Kernel function as similarity functions
- Feature map
Kernels
Linear Model
Weights can be rewritten as a linear combination of training data:
The linear model can then be rewritten:
Dual Formulation
This is the dual hypothesis
Letting
we get:
The significance of
k(u, v)
is a measure of similarity. Thus, we can replace it with other similarity functions.
Kernel Trick
Validity of kernel
For the kernel to be valid, it must be continuous symmetric positive-definite kenrel
With the transformed features, the new dual objective function looks like such:
There is no need to compute the transformation function explicitly.
With the kernel trick, we are then able to substitute the kernel in, allowing us to have SVM with infinite-dimensional features!
The kernel trick affects the dot products between data points, and not directly to dot products between a data point and a cluster mean.
Consider the RBF kernel, with the width hyperparameter
the value of
- when
is smaller, is higher (more similar)
To apply the kernel trick, consider the dot product:
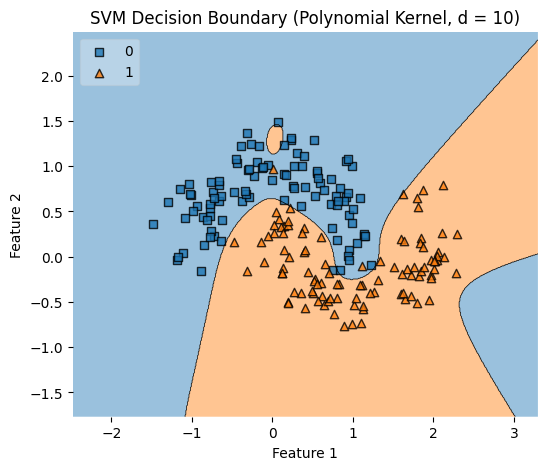
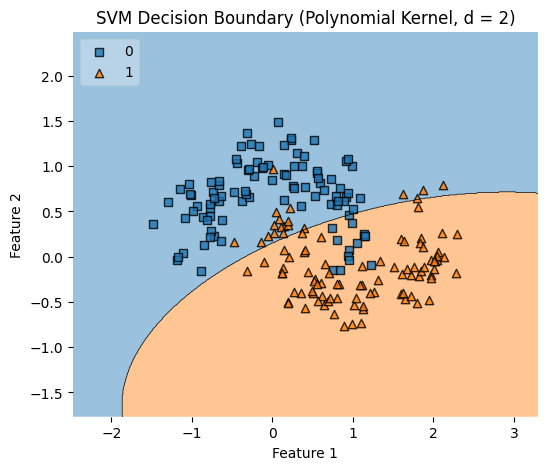
Polynomial Kernel
At the polynomial degree
At the polynomial degree 2,
Thus, we can generalise to degree
Hyperparameters
 |  |
|---|
The higher the degree
- the more complex the model is
- the higher the risk-of-overfitting
- the better the capturing of non-linear intricate relationships.
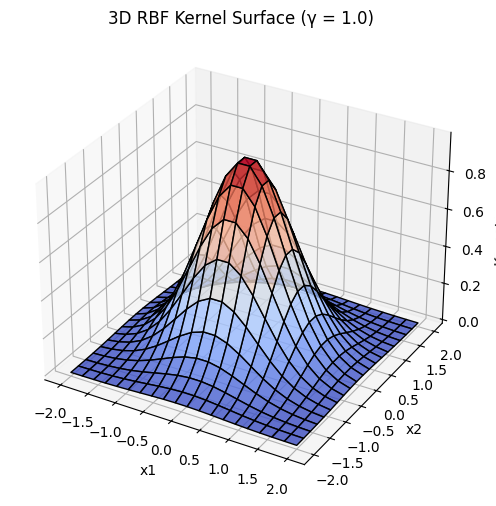
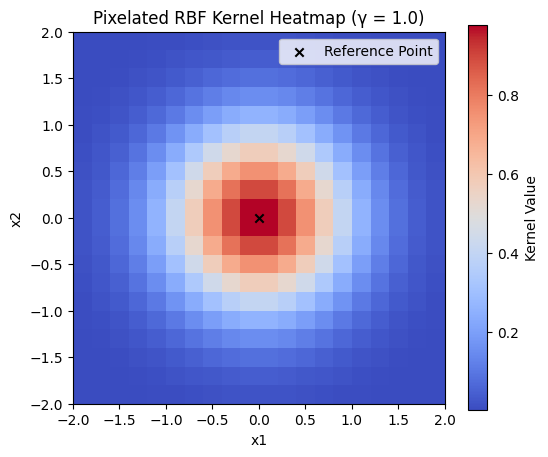
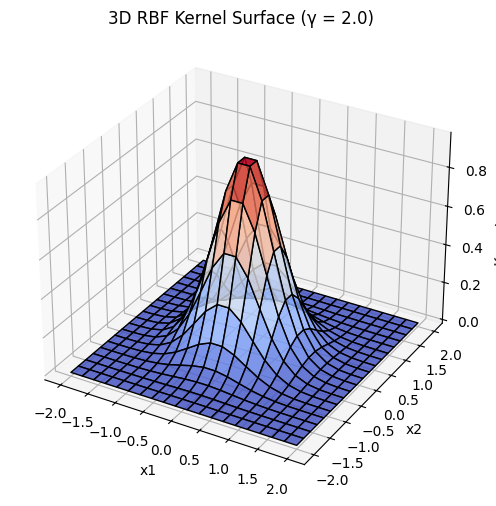
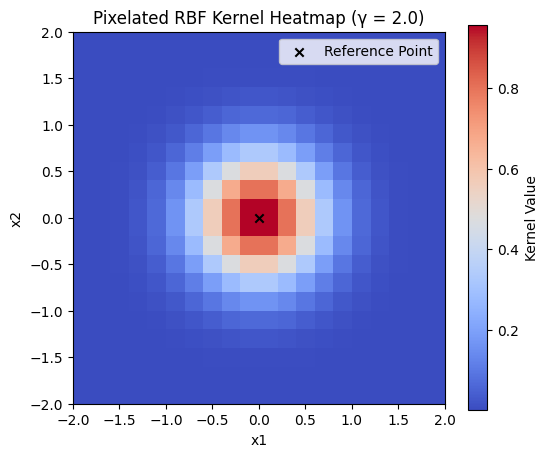
Gaussian Kernel (Radial Basis Function)
In this scenario,
Hyperparameters
Let
 |  |
|---|
 |  |
|---|
Note that the surface becomes smaller as
When
- kernel function decays slowly, meaning points far from reference have high similarity
- smooth, globally connected decision boundaries
- good for simple patterns, may fail to capture fine details, higher risk of underfitting
When
- kernel function decays quickly, meaning only close points have high similarity
- complex, decision boundaries
- good for capturing fine details, higher risk of overfitting
Feature Transformation
The most general case of a feature transformation is to take a
Given
- input vector
of dimension - feature map
of dimension , the hypothesis class is:
Dual Hypothesis with Transformed Features
Recall the dual hypothesis - with the feature mapping function
Note that there is a dot product here, thus this can be generalised to:
Example
Given a non-linear decision boundary, for example:
In the first example, given the feature-transformation function
However, using the function
However,
Kernel Formation
Theorem (informal)
For any valid kernel
, there exists a corresponding feature transformation .